Curve fitting
Introdução
It may be beneficial to approximate a succession of data points to mathematical functions. Technically,
the described operation is generally called curve fitting/regression. The main applications of curve
fitting are the following:
- To summarize, and visualize relationships between input (features/independent variable) and output (target/dependent variable)
- To infer function values in intervals where no data is available
- To transmit information without passing all the values of the data points
- To obtain integrals and derivatives by analytical rather than numerical methods
Given a family of functions that best fits the data points, the problem boils down to obtaining the
best values of the function parameters. The method used depends on the function type. When this
information is not known, it is common to start by plotting the data and try to fit it with various
families of functions.
Taken the example of the data represented in the graph below, it will be described multiple methods to fit to a proper function.

Ordinary least square
Linear regression is one of the simplest algorithms to fit data, using a linear function to describe the
relationship between input and the target variable. It’s clearly inadequate to model our data, but it
will be presented here shortly, for information purpose.
The most common techniques for estimating the parameters in linear regression are based on
minimizing the vertical distance between the estimated plane and the measurements. Among these
techniques, the most popular is Ordinary Least Squares (OLS). The algorithm takes the assumption
that the parameters have equal variance and are uncorrelated. Also assumes the noise to be white and
follows a Gaussian distribution (homoscedasticity).
OLS equation for univariate (having only one variable/input  and a target
and a target  ) linear regression can
) linear regression can
be written as:
![\[ \boldsymbol{\hat{y}} =\beta\boldsymbol{x} \]](https://oncontrol-tech.com/wp-content/ql-cache/quicklatex.com-9788c1b557a87ce6a70313af9f44b926_l3.png "Rendered by QuickLaTeX.com")
We want to minimize  which is the sum of squares of the deviations in
which is the sum of squares of the deviations in  , from each -value. In other words, the goal of OLS is to minimize the difference between the real and the estimate as follows:
, from each -value. In other words, the goal of OLS is to minimize the difference between the real and the estimate as follows:
(1) ![\begin{equation*} E(\beta) = \sum_{i=1}^m [ \hat{y}(x_i) - y_i ]^2 \end{equation*}](https://oncontrol-tech.com/wp-content/ql-cache/quicklatex.com-f6fd1f370b5758f510156f7d934714dd_l3.png "Rendered by QuickLaTeX.com")
 is obtained as by:
is obtained as by:
(2) 
where  is the matrix with the feature values, and
is the matrix with the feature values, and  is its transverse.
is its transverse.
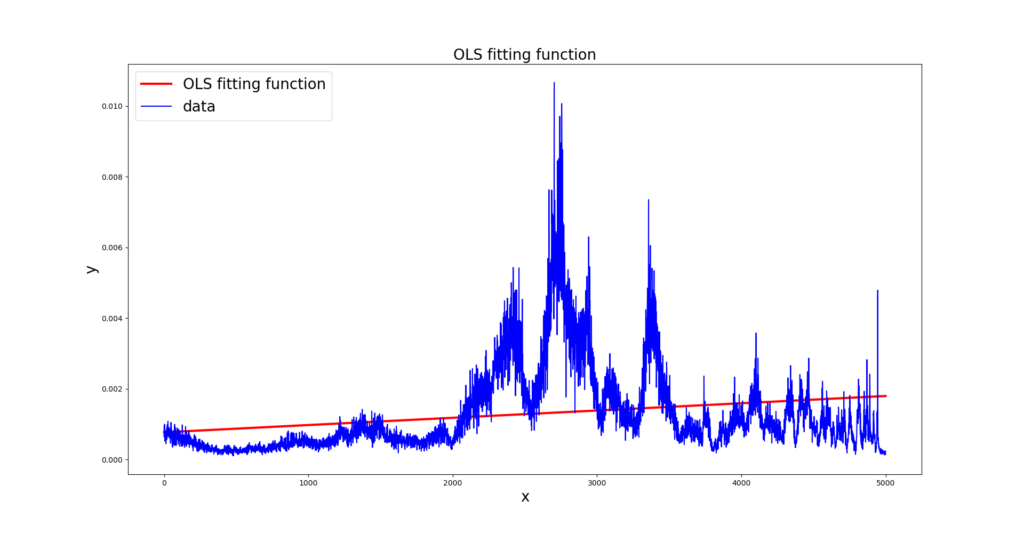
The result of the application of OLS to our example is presented in next Figure.
Polynomial Least square
In order to fit data with functions which are nonlinear, such as polynomials, least-squares fitting can also be utilized. This technique must find the coefficients  of a polynomial function, of degree
of a polynomial function, of degree  , that best fits the data. Let (
, that best fits the data. Let ( ),(
),( ),. . .,(
),. . .,( ) be the data points that need to be approximated by a polynomial function. The least-squares polynomial have the form:
) be the data points that need to be approximated by a polynomial function. The least-squares polynomial have the form:
(3) 
As in the linear case, the coefficients can be obtained by:
(4) 
where:
 =
=  , =
, =  ,
,  =
= 
This equations can be used to compute the coefficients of any linear combination of functions  that best fits data, since that these functions are linearly independent. In this general case, the entries of the matrix
that best fits data, since that these functions are linearly independent. In this general case, the entries of the matrix  are given by
are given by  , for
, for  = 1,2,…,m and
= 1,2,…,m and  = 0,1,…,n.
= 0,1,…,n.
In the Figure below is represented the approximation of our example to a polynomial function of degree  .
.
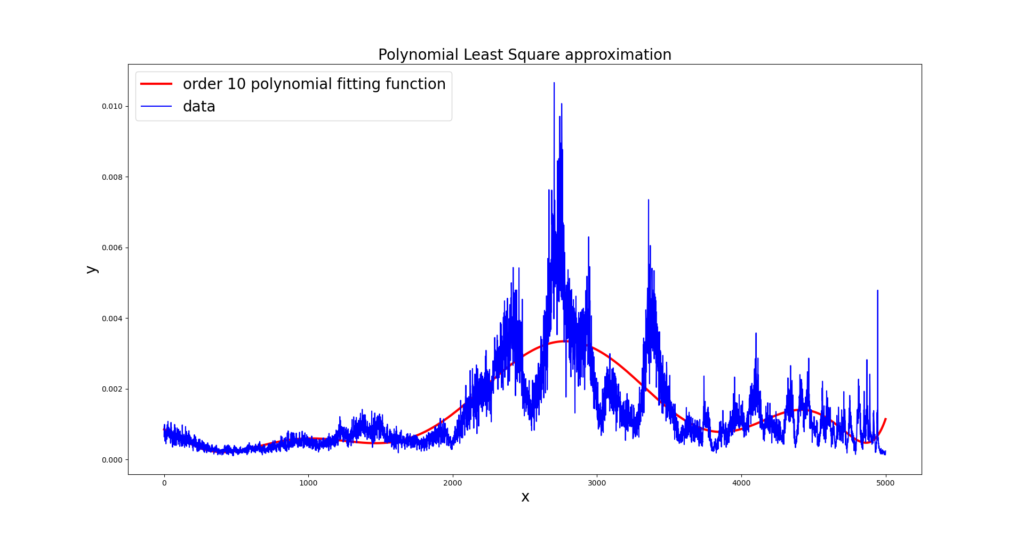
We notice that, even with a high degree (), the polynomial doesn’t fit properly to our data, being not able to fit the main data peaks. This is due to the large variation on data behaviour through the dominium of . Increasing or decreasing polynomial degree doesn’t lead to any better result. In addition, for larger orders of Runge’s phenomena starts to appear, leading to oscillations on the edges of the interval of .
Gaussian Approximation with Levenberg-Marquardt
Levenberg Marquardt is a different method to solve the minimization problem in non-linear least squares curve fitting problems. It is used to obtain the parameters  of any function
of any function  we want to approximate the data to. Levenberg Marquardt algorithm (LM) is a iterative procedure that converges fast, but it finds only local minimum, instead of global minimum. So it deeply depends on the initial guess of the parameters.
we want to approximate the data to. Levenberg Marquardt algorithm (LM) is a iterative procedure that converges fast, but it finds only local minimum, instead of global minimum. So it deeply depends on the initial guess of the parameters.
The objective of this algorithm is to obtain values by minimizing  :
:
(5) ![\begin{equation*} S(\boldsymbol{\beta}) = \sum_{i=1}^m [y_i - f(x_i,\boldsymbol{\beta})]^2 \end{equation*}](https://oncontrol-tech.com/wp-content/ql-cache/quicklatex.com-4b6d051d2dd5ed7188870ce042db7cf3_l3.png "Rendered by QuickLaTeX.com")
In each iteration step, the parameter vector is replaced by a new estimate  . To determine
. To determine  , the function
, the function  is approximated by its linearization:
is approximated by its linearization:

where

Substituting in the equation 5, rearranging and taking the derivative with respect to  and setting the result to zero, we have:
and setting the result to zero, we have:

where  is a damping parameter adjusted at each iteration and
is a damping parameter adjusted at each iteration and  .
.
LM is adaptive because it controls its own damping: it raises the damping parameter if a step fails to reduce the error  ; otherwise it reduces the damping. In this way LM is capable to alternate between a slow descent approach when being far from the minimum and a fast convergence when being at the minimum’s neighborhood. There are several method to update damping parameter .
; otherwise it reduces the damping. In this way LM is capable to alternate between a slow descent approach when being far from the minimum and a fast convergence when being at the minimum’s neighborhood. There are several method to update damping parameter .
To illustrate Levenberg Marquardt application, it was used to approximate our example data points to a set of Gaussian functions. The example is presented in the next Figure.
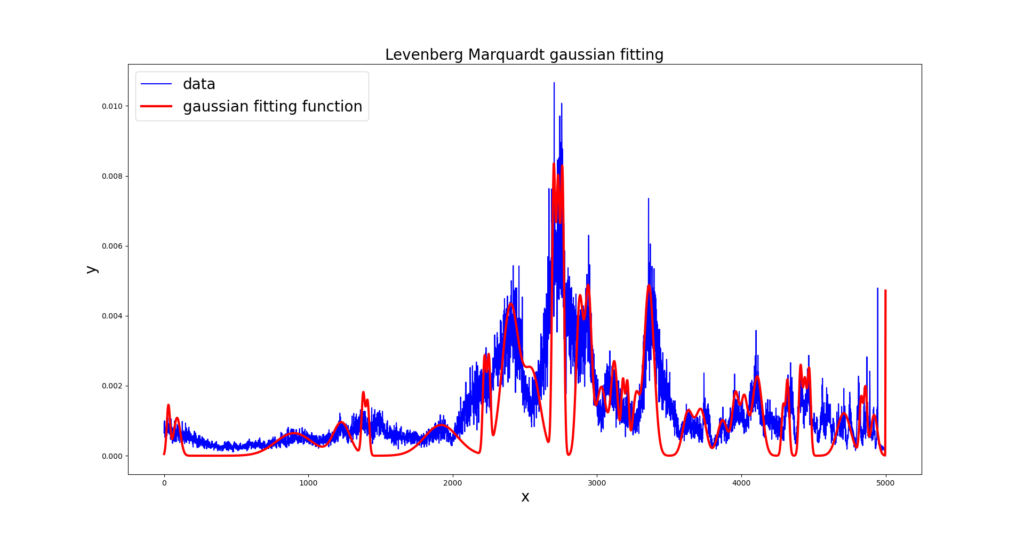
The result was better than polynomial approximation case, as this one captures the main data
peaks. However, the edges of those peaks are not properly adjusted.
Cubic Spline
Cubic spline approximation is a method to fit data to a cubic piecewise polynomial. For that, the data is divided into several segments and each of those segments is modeled by a cubic polynomial. These segments are delimited by nodes, which are the local maximum or minimum of the data set. Each two consecutive nodes are interpolated by a cubic polynomial. If there are n knots points ( ), there are n-1 segments each defined by a cubic polynomial
), there are n-1 segments each defined by a cubic polynomial  , as follow:
, as follow:
![\begin{equation*} S_{n-1}(x)=y_{n-1}+b_{n-1}(x-x_{n-1})+c_{n-1}(x-x_{n-1})^2+d_{n-1}(x-x_{n-1})^3 \text{ } on \text{ } [x_{n-1},x_n] \end{equation*}](https://oncontrol-tech.com/wp-content/ql-cache/quicklatex.com-0f72fe01f8e6076da0354efed1a6844b_l3.png "Rendered by QuickLaTeX.com")
The coefficients for each polynomial are obtained solving the following system of equations that guarantees the continuity and smoothness of the final total spline function.
(6) 
(7) 
(8) 
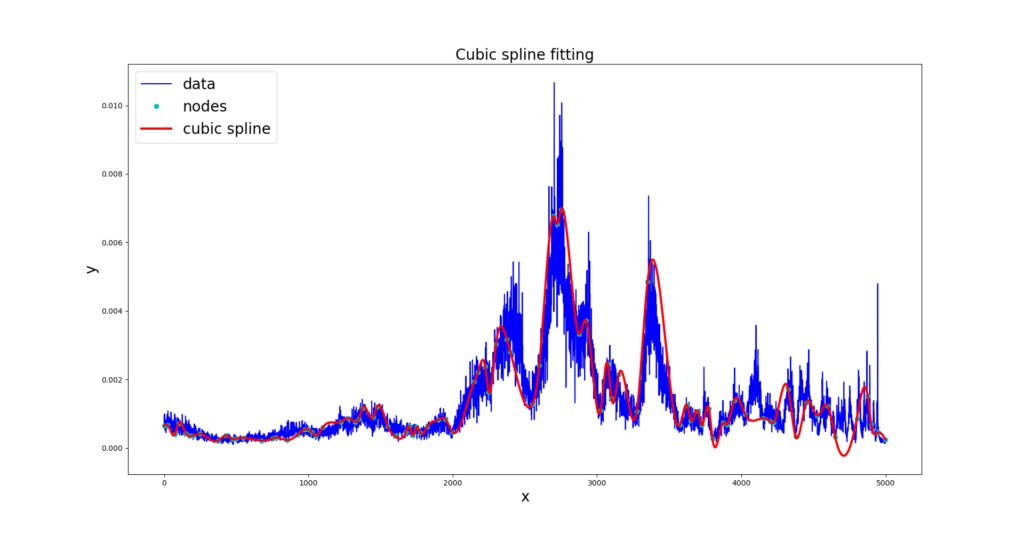
In our example, the system of equations was solved using iterative Jacobi method, and the result is in next Figure.
Conclusion
In this article, the main methods of curve fitting data were discussed. Variations of the methods
presented are often used, and other alternatives are available. Methods based on gradient descent are
an alternative in solving linear and nonlinear regression problems.
Referências
[Hay02] Simon S Haykin. Adaptive filter theory. Pearson Education India, 2002.
[Lou05] Manolis Lourakis. A brief description of the levenberg-marquardt algorithm implemened by levmar. A Brief Description of the Levenberg-Marquardt Algorithm Implemented by Levmar, 4, 01 2005.
[Win] Natural cubic splines implementation with python. https://medium.com/eatpredlove/natural-cubic-splines-implementation-with-python-edf68feb57aa. Accessed: 2022-12-05.